
.jpg)

OpenGL陣営におけるLow-overhead APIとして策定された「Vulkan」を軽く入門してみたのでメモ
全ソースコードはhttp://github.com/Pctg-x8/vkTest
文中のコードはすべてこちらからの切り張りとなっています。
雑な感想
ぶっちゃけめっちゃ難しいです。どこかで少し漏らしたのですがDirectX12が可愛く見えるくらいには難しいと思います。
環境
Windows 10 + NVIDIA GeForce GTX 650
プログラムのビルドにVisual Studio 2015を使用しています。
流れ
大まかな流れとしては次のようになります。
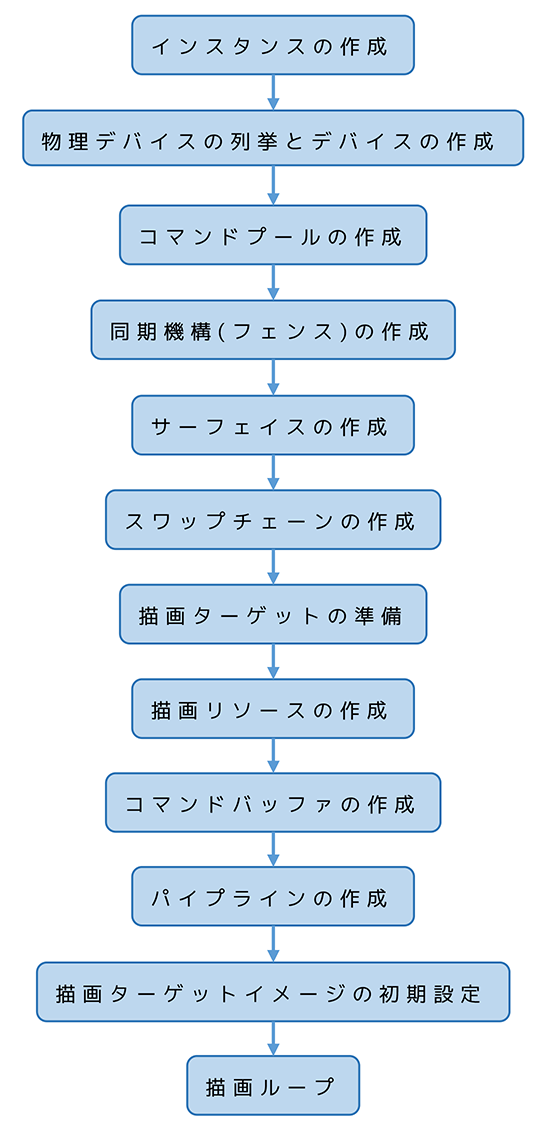
インスタンスの作成
インスタンスを作成するにはvkCreateInstance関数を使います。
VkInstanceCreateInfo instanceInfo{};
VkApplicationInfo appInfo{};
static const char* extensions[] =
{
VK_KHR_SURFACE_EXTENSION_NAME, VK_KHR_WIN32_SURFACE_EXTENSION_NAME,
VK_EXT_DEBUG_REPORT_EXTENSION_NAME
};
static const char* layers[] = { "VK_LAYER_LUNARG_standard_validation" };
appInfo.sType = VK_STRUCTURE_TYPE_APPLICATION_INFO;
appInfo.applicationVersion = VK_MAKE_VERSION(0, 0, 1);
appInfo.pApplicationName = "com.cterm2.vkTest";
appInfo.apiVersion = VK_API_VERSION_1_0;
instanceInfo.sType = VK_STRUCTURE_TYPE_INSTANCE_CREATE_INFO;
instanceInfo.pApplicationInfo = &appInfo;
instanceInfo.enabledExtensionCount = std::size(extensions);
instanceInfo.ppEnabledExtensionNames = extensions;
instanceInfo.enabledLayerCount = std::size(layers);
instanceInfo.ppEnabledLayerNames = layers;
VkInstance instance;
auto res = vkCreateInstance(&instanceInfo, nullptr, &instance);
checkError(res);
VK_KHR_SURFACE_EXTENSION_NAME("VK_KHR_surface")およびVK_KHR_WIN32_SURFACE_EXTENSION_NAME("VK_KHR_win32_surface")の2つのエクステンションはWindows環境で描画をおこなうために必須となります。後者はプラットフォーム依存となります。VK_EXT_DEBUG_REPORT_EXTENSION_NAME("VK_EXT_debug_report")はValidation Layerを使うために必要となります。
デバッグ出力の有効化
図中にはありませんが、Validation Layerを実際に利用するためにはもういくつか手順踏む必要があります。
まずは拡張関数の読み込みです。これはInstanceを経由して読み込むためインスタンスの作成が必須となります。
関数のプロトタイプ型はSDKで宣言されているのでそれを使用します。関数を読み込むにはvkGetInstanceProcAddrを使います。
// load extensions
_vkCreateDebugReportCallbackEXT = reinterpret_cast<PFN_vkCreateDebugReportCallbackEXT>(vkGetInstanceProcAddr(instance, "vkCreateDebugReportCallbackEXT"));
_vkDebugReportMessageEXT = reinterpret_cast<PFN_vkDebugReportMessageEXT>(vkGetInstanceProcAddr(instance, "vkDebugReportMessageEXT"));
_vkDestroyDebugReportCallbackEXT = reinterpret_cast<PFN_vkDestroyDebugReportCallbackEXT>(vkGetInstanceProcAddr(instance, "vkDestroyDebugReportCallbackEXT"));
次にデバッグ出力を処理するオブジェクトを作成します。オブジェクトを作成するには拡張関数のvkCreateDebugReportCallbackEXTを使います。
VkDebugReportCallbackCreateInfoEXT callbackInfo{};
callbackInfo.sType = VK_STRUCTURE_TYPE_DEBUG_REPORT_CALLBACK_CREATE_INFO_EXT;
callbackInfo.flags = VK_DEBUG_REPORT_ERROR_BIT_EXT | VK_DEBUG_REPORT_WARNING_BIT_EXT
| VK_DEBUG_REPORT_PERFORMANCE_WARNING_BIT_EXT | VK_DEBUG_REPORT_INFORMATION_BIT_EXT;
callbackInfo.pfnCallback = &debugCallback;
VkDebugReportCallbackEXT callback;
auto res = _vkCreateDebugReportCallbackEXT(instance.get(), &callbackInfo, nullptr, &callback);
INFORMATION_BIT(VK_DEBUG_REPORT_INFORMATION_BIT_EXT)は念のため指定していますが実際有用な情報は少なく、むしろ重要な情報を圧迫してしまうため指定しないことをお勧めします。
ここでコールバックとして指定しているdebugCallbackはサンプルでは次のように定義してあります。
VKAPI_ATTR VkBool32 VKAPI_CALL debugCallback(VkDebugReportFlagsEXT flags, VkDebugReportObjectTypeEXT, uint64_t object,
size_t location, int32_t messageCode, const char* pLayerPrefix, const char* pMessage, void* pUserData)
{
// OutputDebugString(L"Message Code: "); OutputDebugString(std::to_wstring(messageCode).c_str()); OutputDebugString(L"\n");
OutputDebugString(L"Vulkan DebugCall: "); OutputDebugStringA(pMessage); OutputDebugString(L"\n");
return VK_FALSE;
}
受け取ったメッセージをそのままWindowsのデバッガに出力しているだけです。
物理デバイスの列挙とデバイスの作成
Vulkanのデバイスを作成するために、まずコンピュータに接続されている物理的なグラフィックスデバイスを調べる必要があります。物理デバイスを列挙するにはvkEnumeratePhysicalDevicesを使います。Vulkanの列挙系APIはWin32, POSIXのそれと似た仕様になっており、要素数へのポインタ(uint32_t*)と要素を格納する領域へのポインタを受け取るようになっています。格納先にnullptrを指定すれば要素数が取れます。
uint32_t adapterCount;
auto res = vkEnumeratePhysicalDevices(instance.get(), &adapterCount, nullptr);
checkError(res);
auto adapters = std::make_unique<VkPhysicalDevice[]>(adapterCount);
res = vkEnumeratePhysicalDevices(instance.get(), &adapterCount, adapters.get());
checkError(res);
OutputDebugString(L"=== Physical Device Enumeration ===\n");
for (uint32_t i = 0; i < adapterCount; i++)
{
static VkPhysicalDeviceProperties props;
static VkPhysicalDeviceMemoryProperties memProps;
vkGetPhysicalDeviceProperties(adapters[i], &props);
vkGetPhysicalDeviceMemoryProperties(adapters[i], &memProps);
OutputDebugString(L"#"); OutputDebugString(std::to_wstring(i).c_str()); OutputDebugString(L": \n");
OutputDebugString(L" Name: "); OutputDebugStringA(props.deviceName); OutputDebugString(L"\n");
OutputDebugString(L" API Version: "); OutputDebugString(std::to_wstring(props.apiVersion).c_str()); OutputDebugString(L"\n");
}
return adapters[0];
サンプルでは一番目に列挙された物理デバイスをデフォルトのものとして使用しています。マルチGPU環境などに対応する場合はVulkanのDeviceを作成する前にユーザーに選ばせるなどの手段をとるとよいと思います。
デバイスを作成するためにはvkCreateDeviceを使います。
VkDeviceCreateInfo devInfo{};
VkDeviceQueueCreateInfo queueInfo{};
// Search queue family index for Graphics Queue
uint32_t propertyCount, queueFamilyIndex = 0xffffffff;
vkGetPhysicalDeviceQueueFamilyProperties(pDev, &propertyCount, nullptr);
auto properties = std::make_unique<VkQueueFamilyProperties[]>(propertyCount);
vkGetPhysicalDeviceQueueFamilyProperties(pDev, &propertyCount, properties.get());
for (uint32_t i = 0; i < propertyCount; i++)
{
if ((properties[i].queueFlags & VK_QUEUE_GRAPHICS_BIT) != 0)
{
queueFamilyIndex = i;
break;
}
}
if (queueFamilyIndex == 0xffffffff) throw std::runtime_error("No Graphics queues available on current device.");
const char* layers[] = { "VK_LAYER_LUNARG_standard_validation" };
const char* extensions[] = { "VK_KHR_swapchain" };
static float qPriorities[] = { 0.0f };
queueInfo.sType = VK_STRUCTURE_TYPE_DEVICE_QUEUE_CREATE_INFO;
queueInfo.queueCount = 1;
queueInfo.queueFamilyIndex = queueFamilyIndex;
queueInfo.pQueuePriorities = qPriorities;
devInfo.sType = VK_STRUCTURE_TYPE_DEVICE_CREATE_INFO;
devInfo.queueCreateInfoCount = 1;
devInfo.pQueueCreateInfos = &queueInfo;
devInfo.enabledLayerCount = std::size(layers);
devInfo.ppEnabledLayerNames = layers;
devInfo.enabledExtensionCount = std::size(extensions);
devInfo.ppEnabledExtensionNames = extensions;
VkDevice device;
auto res = vkCreateDevice(pDev, &devInfo, nullptr, &device);
checkError(res);
前半はグラフィックス用のデバイスキューのファミリー番号を取得しています。DirectX12ではグラフィックス用とコンピュート用のキューが一緒になっていましたがVulkanでは分かれているようです。
後半はデバイスの作成となります。構造体に必要なデータを入れて関数を呼び出します。VK_KHR_swapchainエクステンションはスワップチェーンを使用するために必要です。
コマンドプールの作成
このあたりは順番が前後しても多少かまいません。コマンドプール(DirectX12でいうところのCommandAllocator)を作成するにはvkCreateCommandPoolを使います。
VkCommandPoolCreateInfo info{};
info.sType = VK_STRUCTURE_TYPE_COMMAND_POOL_CREATE_INFO;
info.queueFamilyIndex = this->queueFamilyIndex;
info.flags = VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BIT;
VkCommandPool object;
auto res = vkCreateCommandPool(this->pInternal.get(), &info, nullptr, &object);
checkError(res);
VK_COMMAND_POOL_CREATE_RESET_COMMAND_BUFFER_BITを指定するとコマンドバッファごとにリセットを行うことができるようになります。
CommandPoolとCommandAllocator(DirectX12)の違いは、コマンドバッファ(リスト)の割り当てを行うのかコマンド自体の割り当てを行うのかということです。個々のコマンドについてCommandPoolは変換などの処理は行いません。
同期機構(フェンス)の作成
DirectX12にも登場する、CPUとGPUの同期用オブジェクトの一つであるフェンス(VkFence)を作成します。フェンスを作るにはvkCreateFenceを使います。
VkFenceCreateInfo finfo{};
finfo.sType = VK_STRUCTURE_TYPE_FENCE_CREATE_INFO;
VkFence fence;
auto res = vkCreateFence(this->pInternal.get(), &finfo, nullptr, &fence);
checkError(res);
サーフェイスの作成
HWNDからサーフェイスを作成することができます。これはインスタンスから作成できるのでデバイスの作成より前に行っても構いません。サーフェイスを作るにはvkCreateWin32SurfaceKHRを使います。標準APIではないため拡張プレフィクス(KHR)が末尾についています。
VkWin32SurfaceCreateInfoKHR surfaceInfo{};
surfaceInfo.sType = VK_STRUCTURE_TYPE_WIN32_SURFACE_CREATE_INFO_KHR;
surfaceInfo.hinstance = GetModuleHandle(nullptr);
surfaceInfo.hwnd = hWnd;
VkSurfaceKHR surface;
auto res = vkCreateWin32SurfaceKHR(instance.get(), &surfaceInfo, nullptr, &surface);
checkError(res);
スワップチェーンの作成
OpenGLには存在していない概念です。スワップチェーンを作成するにはvkCreateSwapchainKHRを使います。
VkSwapchainCreateInfoKHR scinfo{};
VkBool32 surfaceSupported;
vkGetPhysicalDeviceSurfaceSupportKHR(this->pDevRef, this->queueFamilyIndex, surface.get(), &surfaceSupported);
VkSurfaceCapabilitiesKHR surfaceCaps;
vkGetPhysicalDeviceSurfaceCapabilitiesKHR(this->pDevRef, surface.get(), &surfaceCaps);
uint32_t surfaceFormatCount;
vkGetPhysicalDeviceSurfaceFormatsKHR(this->pDevRef, surface.get(), &surfaceFormatCount, nullptr);
auto surfaceFormats = std::make_unique<VkSurfaceFormatKHR[]>(surfaceFormatCount);
vkGetPhysicalDeviceSurfaceFormatsKHR(this->pDevRef, surface.get(), &surfaceFormatCount, surfaceFormats.get());
uint32_t presentModeCount;
vkGetPhysicalDeviceSurfacePresentModesKHR(this->pDevRef, surface.get(), &presentModeCount, nullptr);
auto presentModes = std::make_unique<VkPresentModeKHR[]>(presentModeCount);
vkGetPhysicalDeviceSurfacePresentModesKHR(this->pDevRef, surface.get(), &presentModeCount, presentModes.get());
for (uint32_t i = 0; i < surfaceFormatCount; i++)
{
auto c = surfaceFormats[i];
OutputDebugString(L"Supported Format Check...");
}
scinfo.sType = VK_STRUCTURE_TYPE_SWAPCHAIN_CREATE_INFO_KHR;
scinfo.surface = surface.get();
scinfo.minImageCount = 2;
scinfo.imageFormat = VK_FORMAT_B8G8R8A8_UNORM;
scinfo.imageColorSpace = VK_COLORSPACE_SRGB_NONLINEAR_KHR;
scinfo.imageExtent.width = 640;
scinfo.imageExtent.height = 480;
scinfo.imageArrayLayers = 1;
scinfo.imageUsage = VK_IMAGE_USAGE_COLOR_ATTACHMENT_BIT;
scinfo.imageSharingMode = VK_SHARING_MODE_EXCLUSIVE;
scinfo.compositeAlpha = VK_COMPOSITE_ALPHA_OPAQUE_BIT_KHR;
scinfo.preTransform = VK_SURFACE_TRANSFORM_IDENTITY_BIT_KHR;
scinfo.presentMode = VK_PRESENT_MODE_FIFO_KHR;
scinfo.clipped = VK_TRUE;
VkSwapchainKHR object;
auto res = vkCreateSwapchainKHR(this->pInternal.get(), &scinfo, nullptr, &object);
checkError(res);
前半はひたすら関数を呼び出していますがなくても一応動いちゃったりします(呼び出さない場合はValidation Layerから警告が届きます)。フォーマットに関してですが、Windows 10+GeForce GTX 650の環境ではBGRAの順のフォーマットしかサポートされていないようでした(DirectX12ではRGBAが使えた記憶)。使えるフォーマットが限られているプラットフォームが存在する場合があるかもしれないのでフォーマットだけは関数を使って確認しておくとよいと思います(vkGetPhysicalDeviceSurfaceFormatsKHRで列挙できます)。
描画ターゲットの準備
DirectX12でも必要な手順となりますがVulkanのほうが少しだけ複雑になっています。
まずは描画先のイメージオブジェクトをスワップチェーンから取得します。vkGetSwapchainImagesKHRを使います。
uint32_t imageCount;
auto res = vkGetSwapchainImagesKHR(this->pInternal.get(), chain.get(), &imageCount, nullptr);
checkError(res);
auto images = std::make_unique<VkImage[]>(imageCount);
res = vkGetSwapchainImagesKHR(this->pInternal.get(), chain.get(), &imageCount, images.get());
checkError(res);
列挙によって得られるオブジェクトの数がVkSwapchainCreateInfoKHR::minImageCountと必ずしも一致しない場合があるのでオブジェクト数は必ず取得するようにするのがよいと思います。
次にイメージビューと呼ばれるものを作成します。DirectX12にも似たような「ビュー」というものが存在しますがVulkanのそれは少しばかり抽象的なものとなります。
イメージオブジェクトからイメージビューを作成するにはvkCreateImageViewを使用します。
VkImageViewCreateInfo vinfo{};
vinfo.sType = VK_STRUCTURE_TYPE_IMAGE_VIEW_CREATE_INFO;
vinfo.image = images.first[i];
vinfo.viewType = VK_IMAGE_VIEW_TYPE_2D;
vinfo.format = VK_FORMAT_B8G8R8A8_UNORM;
vinfo.components = {
VK_COMPONENT_SWIZZLE_R, VK_COMPONENT_SWIZZLE_G, VK_COMPONENT_SWIZZLE_B, VK_COMPONENT_SWIZZLE_A
};
vinfo.subresourceRange = { VK_IMAGE_ASPECT_COLOR_BIT, 0, 1, 0, 1 };
VkImageView view;
auto res = vkCreateImageView(this->pInternal.get(), &vinfo, nullptr, &view);
checkError(res);
Vulkanにおける「ビュー」とはほぼそのままの意味(GPUに対してオブジェクトをどのように使用するかを指定する)でとらえて大丈夫だと思います。
続いてレンダーパスの設定です。これがVulkanにのみ存在する概念で理解と立ち回りが若干難しいです。Vulkanにおけるレンダーパスは「DirectX12のパイプラインステートの一部である」と考えてしまうのがとりあえずいいかなと思います。パイプラインステートのうち各アタッチメント(描画ターゲットイメージ)をどのように使用するのかとパス間の依存性を記述します。パス間の依存性については普通は使わないので無視して大丈夫だと思います。
レンダーパスを作成するにはvkCreateRenderPassを使用します。
VkAttachmentDescription attachmentDesc{};
VkAttachmentReference attachmentRef{};
attachmentDesc.format = VK_FORMAT_B8G8R8A8_UNORM;
attachmentDesc.samples = VK_SAMPLE_COUNT_1_BIT;
attachmentDesc.loadOp = VK_ATTACHMENT_LOAD_OP_CLEAR;
attachmentDesc.storeOp = VK_ATTACHMENT_STORE_OP_STORE;
attachmentDesc.initialLayout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;
attachmentDesc.finalLayout = VK_IMAGE_LAYOUT_PRESENT_SRC_KHR;
attachmentRef.attachment = 0;
attachmentRef.layout = VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL;
VkSubpassDescription subpass{};
VkRenderPassCreateInfo renderPassInfo{};
subpass.pipelineBindPoint = VK_PIPELINE_BIND_POINT_GRAPHICS;
subpass.colorAttachmentCount = 1;
subpass.pColorAttachments = &attachmentRef;
renderPassInfo.sType = VK_STRUCTURE_TYPE_RENDER_PASS_CREATE_INFO;
renderPassInfo.attachmentCount = 1;
renderPassInfo.pAttachments = &attachmentDesc;
renderPassInfo.subpassCount = 1;
renderPassInfo.pSubpasses = &subpass;
VkRenderPass object;
auto res = vkCreateRenderPass(this->pInternal.get(), &renderPassInfo, nullptr, &object);
checkError(res);
一つのレンダーパスは複数のサブパスを抱合し、基本的にはそれぞれが独立しています(普通のマルチレンダーターゲット)。
レンダーパスまで作成できたら最後にフレームバッファを作成します。これでイメージに対して描画をすることができます。OpenGLではデフォルトのフレームバッファというものが暗黙のうちに存在していましたがVulkanではすべて自前で作成する必要があります。
フレームバッファを作成するにはvkCreateFramebufferを使用します。
// Common Properties
VkFramebufferCreateInfo fbinfo{};
VkImageView attachmentViews[1];
fbinfo.sType = VK_STRUCTURE_TYPE_FRAMEBUFFER_CREATE_INFO;
fbinfo.attachmentCount = 1;
fbinfo.renderPass = renderPass.get();
fbinfo.pAttachments = attachmentViews;
fbinfo.width = 640;
fbinfo.height = 480;
fbinfo.layers = 1;
for (uint32_t i = 0; i < size(imageViews); i++)
{
attachmentViews[0] = imageViews.first[i].get();
VkFramebuffer fb;
auto res = vkCreateFramebuffer(this->pInternal.get(), &fbinfo, nullptr, &fb);
checkError(res);
buffers[i] = Framebuffer(this->pInternal.get(), fb, &vkDestroyFramebuffer);
}
ここまで登場したImageView, RenderPass(SubPass), Framebufferの関係の簡単な概念図は以下の通りになります。

描画リソースの作成
いわゆる「メッシュ」の情報を作成するフェーズとなります。Vulkanのリソース作成はかなり柔軟性が高く、その分入門するのに難しくなっています。Vulkanでは「論理的なバッファオブジェクト作成」および「そのデータのためのメモリ確保」と手順がわかれています。
サンプルでは適当な三角形を描画させるためシンプルな頂点バッファを作成しています。
まずは論理的なオブジェクトであるバッファ(VkBuffer)を作成します。
VkBufferCreateInfo bufferInfo{};
bufferInfo.sType = VK_STRUCTURE_TYPE_BUFFER_CREATE_INFO;
bufferInfo.usage = VK_BUFFER_USAGE_VERTEX_BUFFER_BIT;
bufferInfo.size = sizeof(VertexData) * nElements;
bufferInfo.sharingMode = VK_SHARING_MODE_EXCLUSIVE;
VkBuffer buffer;
auto res = vkCreateBuffer(this->pInternal.get(), &bufferInfo, nullptr, &buffer);
checkError(res);
次にGPU内のメモリを確保します。このときマップ時にホスト(CPU)から見えるメモリに確保しないと正常にマップ操作が行われませんので正しいメモリタイプインデックスを指定します。この情報は物理デバイスに対してvkGetPhysicalDeviceMemoryPropertiesを使用することで取得できます。
メモリを確保したらバッファオブジェクトと関連付けを行います(vkBindBufferMemoryを使います)。
// Memory Allocation
VkMemoryRequirements memreq;
VkMemoryAllocateInfo allocInfo{};
vkGetBufferMemoryRequirements(this->pInternal.get(), buffer, &memreq);
allocInfo.sType = VK_STRUCTURE_TYPE_MEMORY_ALLOCATE_INFO;
allocInfo.allocationSize = memreq.size;
allocInfo.memoryTypeIndex = UINT32_MAX;
// Search memory index can be visible from host
for (size_t i = 0; i < this->memProps.memoryTypeCount; i++)
{
if ((this->memProps.memoryTypes[i].propertyFlags & VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT) != 0)
{
allocInfo.memoryTypeIndex = i;
break;
}
}
if (allocInfo.memoryTypeIndex == UINT32_MAX) throw std::runtime_error("No found available heap.");
VkDeviceMemory mem;
res = vkAllocateMemory(this->pInternal.get(), &allocInfo, nullptr, &mem);
checkError(res);
// Set data
uint8_t* pData;
res = vkMapMemory(this->pInternal.get(), mem, 0, sizeof(VertexData) * nElements, 0, reinterpret_cast<void**>(&pData));
checkError(res);
memcpy(pData, data, sizeof(VertexData) * nElements);
vkUnmapMemory(this->pInternal.get(), mem);
// Associate memory to buffer
res = vkBindBufferMemory(this->pInternal.get(), buffer, mem, 0);
checkError(res);
バッファオブジェクト作成とメモリ確保が分かれていることからもわかるとは思いますが、一つの確保済みメモリブロックを複数のバッファオブジェクトで使用することが可能です。というよりNVIDIAの解説1ではその方法がベストであるとして記述されています。
コマンドバッファの作成
GPUへのコマンドのリストを作成, 保持するための重要なオブジェクトです。コマンドバッファを作成するにはvkAllocateCommandBuffersを使用します。
VkCommandBufferAllocateInfo cbAllocInfo{};
cbAllocInfo.sType = VK_STRUCTURE_TYPE_COMMAND_BUFFER_ALLOCATE_INFO;
cbAllocInfo.commandPool = pool.get();
cbAllocInfo.level = VK_COMMAND_BUFFER_LEVEL_PRIMARY;
cbAllocInfo.commandBufferCount = nBuffers;
auto buffers = CommandBuffers(this->pInternal.get(), pool.get(), nBuffers);
auto res = vkAllocateCommandBuffers(this->pInternal.get(), &cbAllocInfo, buffers.data());
checkError(res);
関数名が複数形になっていることからもわかる通り、複数のコマンドバッファを一気に作成することができるようになっています。サンプルでは結局1つしか使用していないのですが、例えばスワップチェーンの各バッファにひとつコマンドバッファを割り当てておき描画時にはそのバッファを送信するだけになるためCPUの負荷を下げることが可能だったりします。
パイプラインの作成
VulkanはじめLow-overhead APIの要であり最も設定項目が多く面倒になりがちなパイプラインの設定を行います。Vulkanのパイプラインは先に出たRenderPassが存在する関係などによりDirectX12のそれより小さなものとなります...のはずなのですがDirectX12のパイプライン初期化よりコード量が肥大化しています。
Vulkanのパイプライン作成手順は、おおまかに
- シェーダモジュールの作成
- パイプラインレイアウトの作成
-
パイプラインキャッシュの作成(11/19修正: この手順は不要です。) - パイプライン本体の作成
という手順に分かれています。
まずはシェーダモジュールの作成です。Vulkanではシェーダを事前にコンパイルしておくことが可能になりましたのでバイナリを読んでモジュールを作成するだけです。
const auto bin = BinaryLoader::load(path);
VkShaderModuleCreateInfo shaderInfo{};
shaderInfo.sType = VK_STRUCTURE_TYPE_SHADER_MODULE_CREATE_INFO;
shaderInfo.codeSize = bin.second;
shaderInfo.pCode = reinterpret_cast<uint32_t*>(bin.first.get());
VkShaderModule mod;
auto res = vkCreateShaderModule(this->pInternal.get(), &shaderInfo, nullptr, &mod);
checkError(res);
モジュールの段階では頂点, フラグメント, ジオメトリなどの区別が存在しないため簡単に自動化することができると思います。
続いてパイプラインレイアウトの作成です。DirectX12でいうところのルートシグネチャのようなものです。
VkPipelineLayoutCreateInfo pLayoutInfo{};
pLayoutInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO;
VkPipelineLayout pLayout;
auto res = vkCreatePipelineLayout(this->pInternal.get(), &pLayoutInfo, nullptr, &pLayout);
checkError(res);
サンプルではシェーダ定数を使っていないため構造体の初期化はこれだけです。
次にパイプラインキャッシュの作成です。(11/19修正: この手順は不要です。)
VkPipelineCacheCreateInfo cacheInfo{};
cacheInfo.sType = VK_STRUCTURE_TYPE_PIPELINE_CACHE_CREATE_INFO;
VkPipelineCache cache;
auto res = vkCreatePipelineCache(this->pInternal.get(), &cacheInfo, nullptr, &cache);
checkError(res);
最後にパイプライン本体の作成です。サンプルでは深度/ステンシルバッファを使用していないのと、ブレンディングを使用していないためもっとも単純なセットアップになっているのですがそれでも60行近くあるため割愛します。
要点としてはDynamicStateというものが存在しており、たとえばツールアプリケーションなどを作成する場合(いないかな?)、ウィンドウや分割ウィンドウの幅などが動的に変化するためビューポートおよびシザー矩形を動的に設定する必要が出てくる場合があります。その時にDynamicStateをしっかり設定しておかないとコマンドリスト中で変更できませんので注意です。
(11/19追記: パイプラインキャッシュを使用しない場合はvkCreateGraphicsPipelinesの第二引数をVK_NULL_HANDLEにします。)
描画ターゲットイメージの初期設定
Swapchainから取得したばかりのイメージは、そのままでは描画にも表示にも使用できない状態になっていますのでしっかりと初期設定を行う必要があります。
auto barriers = std::make_unique<VkImageMemoryBarrier[]>(size(images));
for (uint32_t i = 0; i < size(images); i++)
{
VkImageMemoryBarrier barrier{};
barrier.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
barrier.oldLayout = VK_IMAGE_LAYOUT_UNDEFINED;
barrier.newLayout = VK_IMAGE_LAYOUT_PRESENT_SRC_KHR;
barrier.image = images.first[i];
barrier.subresourceRange.aspectMask = VK_IMAGE_ASPECT_COLOR_BIT;
barrier.subresourceRange.layerCount = 1;
barrier.subresourceRange.levelCount = 1;
barriers[i] = barrier;
}
vkCmdPipelineBarrier(buffer, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT,
0, 0, nullptr, 0, nullptr, size(images), barriers.get());
この設定は未指定状態から表示用状態へとメモリバリアを張る設定となっています。GPUはマルチコアアーキテクチャなのでしっかりとメモリバリアを張っておかないとデータ競合が発生しまくって整合性が取れなくなってしまいます。
これはGPUへのコマンドとなっているためこの後に命令を送信して(vkQueueSubmitを使います)完了を待機する必要があります。ここではやることがないのでvkQueueWaitIdleを使って雑に待機しています。
また、描画を開始する前に次に描画すべきターゲットのインデックス番号を取得しておきます。もしかしたら適当に決め打ったイメージが準備できていない可能性があるためです。
auto res = vkAcquireNextImageKHR(this->pInternal.get(), swapchain.get(),
UINT64_MAX, VK_NULL_HANDLE, fence.get(), &nextFrameIndex);
Vulkan::checkError(res);
res = vkWaitForFences(this->pInternal.get(), 1, &fence.get(), VK_FALSE, UINT64_MAX);
Vulkan::checkError(res);
res = vkResetFences(this->pInternal.get(), 1, &fence.get());
Vulkan::checkError(res);
ここではフェンスを使用しています。リソース(イメージ)が使用可能になるとフェンスがシグナル状態になるのでそれを待機(vkWaitForFences)します。フェンスは自動で非シグナル化しないのでvkResetFencesでリセットしてあげます。
描画ループ
サンプルの描画部分(g_RenderFuncの中身)を載せておきます。
static VkViewport vp = { 0.0f, 0.0f, 640.0f, 480.0f, 0.0f, 1.0f };
static VkRect2D sc = { { 0, 0 }, { 640, 480 } };
static VkDeviceSize offsets[] = { 0 };
Vulkan::beginCommandWithFramebuffer(cmdBuffers[0], frameBuffers.first[currentFrameIndex]);
Vulkan::barrierResource(cmdBuffers[0], images.first[currentFrameIndex],
VK_PIPELINE_STAGE_TOP_OF_PIPE_BIT, VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT,
VK_ACCESS_MEMORY_READ_BIT, VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT,
VK_IMAGE_LAYOUT_PRESENT_SRC_KHR, VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL);
Vulkan::beginRenderPass(cmdBuffers[0], frameBuffers.first[currentFrameIndex], renderPass);
vkCmdBindPipeline(cmdBuffers[0], VK_PIPELINE_BIND_POINT_GRAPHICS, pipeline.get());
vkCmdSetViewport(cmdBuffers[0], 0, 1, &vp);
vkCmdSetScissor(cmdBuffers[0], 0, 1, &sc);
vkCmdBindVertexBuffers(cmdBuffers[0], 0, 1, &vertices.first.get(), offsets);
vkCmdDraw(cmdBuffers[0], 3, 1, 0, 0);
vkCmdEndRenderPass(cmdBuffers[0]);
/*Vulkan::barrierResource(cmdBuffers[0], images.first[currentFrameIndex],
VK_PIPELINE_STAGE_COLOR_ATTACHMENT_OUTPUT_BIT, VK_PIPELINE_STAGE_BOTTOM_OF_PIPE_BIT,
VK_ACCESS_COLOR_ATTACHMENT_WRITE_BIT, VK_ACCESS_MEMORY_READ_BIT,
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL, VK_IMAGE_LAYOUT_PRESENT_SRC_KHR);*/
vkEndCommandBuffer(cmdBuffers[0]);
// Submit and Wait with Fences
device.submitCommands(cmdBuffers[0], fence);
switch (device.waitForFence(fence))
{
case VK_SUCCESS: device.present(swapchain, currentFrameIndex); break;
case VK_TIMEOUT: throw std::runtime_error("Command execution timed out."); break;
default: OutputDebugString(L"waitForFence returns unknown value.\n");
}
device.resetFence(fence);
// Acquire next
device.acquireNextImageAndWait(swapchain, fence, currentFrameIndex);
基本的には
- コマンドの記録を特定のフレームバッファに対して開始
- メモリバリアを描画用に張って
- レンダーパスを開始
- パイプラインをグラフィクス用にバインドして
- ビューポート, シザー矩形を設定
- 頂点バッファをバインドして描画コマンドを発行
- レンダーパスを終了してコマンドの記録を終了
という流れでコマンドリストを形成していきます。コマンドプール作成時に個別にリセット可能な設定にしていた場合はコマンドの記録開始と同時にコマンドバッファがリセットされます。また、レンダーパスのアタッチメント設定においてfinalLayoutを表示用に設定しておくとレンダーパス終了時に自動でバリアを張ってくれるので最後にバリア命令を発行しなくてよくなります。
ちなみにですが、この場合は描画対象のインデックス以外変更点がないためコマンドバッファを事前に準備しておき送信するバッファを切り替えるようにしたほうが効率的だったりします。
コマンドの記録が完了したらコマンドの送信を行います。実行完了を待機し、成功したらスワップチェーンを切り替えます(vkQueuePresentKHRを使います)。同じキューに対する命令になっているためもしかしたらコマンド実行完了を待たなくてもよかったりするかもしれませんが試していないのでわかりません。(DirectX12ではここは待たなかった記憶)
スワップチェーンの切り替え命令を発行した後は次のレンダリングに備えて次の描画ターゲットが使えるようになるまで待ちます。
後始末
C++11なのでできればスマートポインタを使って後始末を自動化しましょう。と言いたいところではあるんですが、Vulkanの型の一部は単純なuintへのtypedefとなっているため、そのままではスマートポインタで扱えません。unique_ptr限定になりますがカスタムデリータでpointer型を指定してあげると管理できるようになります(サンプルでは気づかなくて単純なunique_ptrもどきをセルフ実装していますがあまりお勧めはしません)。ちなみにVkInstanceやVkDeviceなどほんとに一部の型は実際にポインタ型なのでそのままスマートポインタで管理することができます。
参考
- Vulkan 1.0.12 + WSI Extensions Specification
- PROJECT ASURA
- GPUOpen